
Stream Processing Systems are one of the most powerful tools you can include in a microservice infrastructure, but from conversations I have had, many developers adopting microservices have not really tackled the subject. This was no fault of the developers, but more a result of documentation that was platform specific and differing terminologies for underlying concepts that are very similar.
I am specifically avoiding any FIFO single stream, non persistent systems like SQS. I am talking specifically about tools that create persistent streams that are tapped into. Three particular systems stick out, that share common characteristics:
What I am about to explain is not the limit of what these systems can do, but where I feel they have significant overlap to categorize them together.
From here on out I will just refer to these like minded systems as SPS. I am also going to use my own terms for concepts in all three systems that share functionality. I will provide a correlation between the three at the end of this article. When I introduce a new term with a correlate it will be in bold italic.
Some Basic Concepts In SPS
A good SPS is designed to scale very large and consume lots of data.
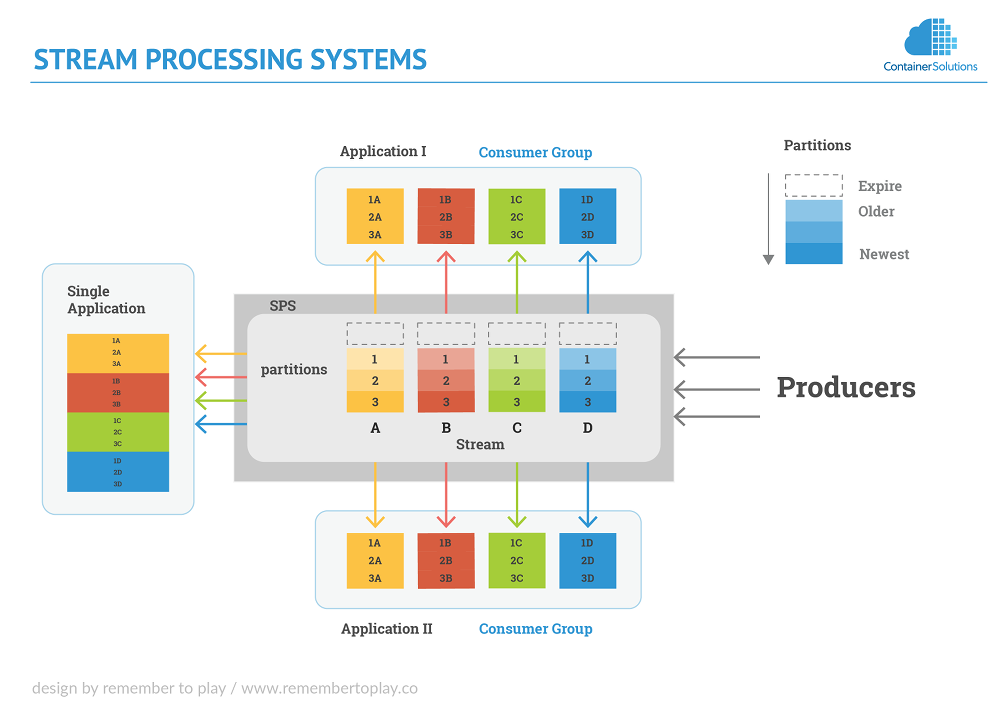
Producers send data to an SPS, and consumers request that data from the system.
When an SPS accepts data from a producer the SPS stores the data with a TTL on a stream. When the TTL is reached the data will expire from the stream.
The stream data is stored on a partition. You can have one or many partitions on a stream. Data can be automatically brokered by the SPS to available partitions or explicitly set by the producer. Partitions increase throughput on the system, but can lead to slow downs and higher costs depending on the system you are using. Any SPS is able to scale partitions up, Kafka does not support scaling down the number of partitions.
If you have multiple partitions and the partitions are not explicitly set by the producer, there is no guaranteed order of messages. Basically all the data is spread across the partitions depending on how the SPS is designed. If the the partition key is explicitly set message ordering can be guaranteed for that partition.
Consumers
Where this system excels is in the manner in which you can consume the data.
One thing to understand is that consumers do not just request the next record, they have to manage their own position in a stream and request that data at a specified index in the stream. All the SPS systems listed have a coordinator to manage your index in the stream or it can be done manually in the application, but using a coordinator allows for easy horizontal scaling into consumer groups.
A consumer group allows you to have multiple instances of the same consumer working off the stream without duplicating record processing.
When using consumer groups there is always a direct ratio of consumers in that group to the number of partitions. The consumers can never exceed that ratio in relation to the number of partitions or those consumers will sit idle, but you can always have more partitions than consumers.
Put simply in a 1 to 1 ratio, if you have 5 partitions and you have started 2 consumers when they deplete one partition they will move to the next. If you have 5 partitions and have 7 consumers, 5 will be assigned to their own partition and the other two will just sit idle.
Delivery
The SPS systems are designed as “at least once delivery” but not “exactly once” or “most once.” Below are some examples of how duplicate messages can be produced.
For the consumer, acknowledgement is sent to the coordinator that a record has been processed. If the consumer crashes between receiving a message and processing the acknowledgement the message will be reprocessed when the consumer recovers.
If the producer sends a message to the SPS and while awaiting an ACK that the SPS has received the message the the network connection is broken. Then the producer attempts to send again. Well if the SPS has received the message but the acknowledgement did not reach the producer, then you will have duplicate records in the SPS.
These duplicate message problems are not just inherent to SPS but can be problematic in any aspect of your distributed system, it is beyond the scope of this article, but something that should be considered in your infrastructure anyway.
Simple
In its simplest form you have one application consuming from a stream. But this adds no benefit over using a traditional queue. It actually increases complexity, since you will be managing your own index manually or with a coordinator.
Even after horizontally scaling a single application it is less complex using a simple queue like SQS.
But we are building microservices, and the whole point of what we are doing is increased flexibility and scalability. So what SQS doesn’t allow us to do is have another application consume the same data at any point in time, including running as cron jobs, and rewinding their own execution.
Multiple Distinct Consumers
Because SPS streams can be persisted and it does not care where an application stands in the stream, we can have multiple applications in their own consumer group that scale horizontally using a coordinator and access the stream at any point. The coordinator maintains the indexes for all the consumers in a consumer group for all consumer groups independently, so each application can consume data at their own speed but you can react to the same data in completely different ways, and if any or all become obsolete or new functionality is needed, you can just add and remove applications and none of your other infrastructure is disturbed.
This can become a very powerful tool.
A Simple Example
So let’s consider a simple ecommerce system.
When a customer completes an order you put the order in your SPS, that is it.
Now you have independent consumers/consumer groups doing the following:
- Save the order in the DB
- Send an email to the customer
- Generate a shipment label with the shipping company
- Update your stock in your ERP
- Add the customer to your CRM
None of the above knows the other even exists. If one goes down the others continue to work, and it is all designed to scale horizontally.
Now consider the sales team just did a promotion. They want to know in real time how the promotion is behaving.You could write another consumer on the stream that just counts the orders with that promotion code. This consumer does not have any impact on your existing infrastructure as it gets its own place on the stream of data.
If your project is greenfield or even a restructure of existing technologies into a microservice environment, you may not have big data on your docket yet… YET. But eventually you will see the need to react quickly to market changes and be able to see real time impacts of your changing business model. At some point in time some forward thinking member of your marketing team will say they want to perform A/B testing.
These SPS systems, if already in place will give your business the flexibility to tap into masses amounts of data as it passes through your infrastructure. Preparing your infrastructure for big data could be several more articles by itself.
What Sets It Apart
What sets SPS systems apart from traditional queues is the flexibility that the persistence of the data provides and the decoupling designed into it.
An SPS acts more like a DB with a TTL on the records (optional for some). You can view it as a linear set of messages, possibly split across partitions where every record has its own reference in the the stream, that can be revisited as long as the TTL has not expired.
There is no coupling between any part of the system. Producers and consumers are completely decoupled from the SPS. Even though the coordinator may appear to work as part of the core SPS it is also decoupled. Some applications can use the coordinator while others may be based on one that you write on your own. You can even write one that traverses the a stream backwards, or one that acts as a buffer on a stream with stronger delivery guarantees.
SPS systems also have the some of the highest performance metrics for traffic ingestion compared to any other comparable systems.
Should you SPS?
That is a decision that must be determined by your team, but it should be one of the primary tools when considering your architecture. I would say an SPS offers you four distinct value propositions for your infrastructure.
- Strong decoupling which allows you to add and remove functionality on top of your established architecture without having to alter what is already in place. It allows for a certain level of future proofing.
- The ability to handle heavy traffic, and to scale horizontally, which serves as a buffer between your infrastructure and traffic spikes.
- The ability to tap into any point in a stream over new data, already consumed data, and to replay history.
- Process resiliency. For example, you will still be able to handle an order if you email service is down.
The major downsides when considering an SPS are things like cost, complexity and support (Kafka ain’t easy). The decision to use an SPS has an affect on your architecture and your application. In a sense, your application becomes coupled to the idea of using an SPS.
Closing and Disclaimers
Whenever vetting a new microservice infrastructure, I always ask myself if an SPS is a good option for interservice communication. Many times it is, but the most push back against it is not a result of the limitations or requirements of what is being built, but the stakeholders not understanding the value proposition it offers, or how it works. With just these three distinct systems offering their own terminology for like minded behavior, the waters get even muddier. So this article is an attempt to try and clarify and or simplify some core concepts.
That being said, this does not cover the gamut of abilities these systems have. All three have multiple levels of integration with other tools and those should be explored as much as possible. This article was only meant to cover the similarities amongst these systems not their full capability.
I have also made some generalizations to emphasize concepts, at the cost of precision.
If you feel another system fits into this paradigm, I welcome suggestions, just be sure to include the name, and the correlate system terminology.
Correlate System Terminology
 |
|
|
|
| Producer | Producer | Producer | Event Publishers |
| Consumer | Consumer | Amazon KinesisStreams Applications | Event Consumers |
| Stream | Topic | Stream | Event Hub |
| Partition | Partition | Shard | Partition |
| Index | Offset | Sequence Number | Partition Key |
| Coordinator | Consumer Groups built into client libraries(ZooKeeper) | Amazon Kinesis ClientLibrary/MultiLangDaemon(DynamoDB) | Worker |
| Consumer Group | Consumer Group | Application | Consumer Group |
*Notes:
I have experience with Kafka and Kinesis but none with Azure outside what I have read in their documentation. Corrections are welcome.
AWS is not very consistent with their terminology, meaning some terms may be represented differently in their documentation.