
[wpdm_package id='5149']
Microservice systems have very different characteristics from previous architectures. Whereas the system as a whole may live for a long time, its components - the containers - do not. They live and die quickly.
This new situation presents new challenges to many areas of software engineering. One of them is monitoring - how can an operator make sure that a system remains healthy if existing monitoring tools are unable to function in this new reality?
In this post I will explore the challenge, and present my ideas on how we can apply the knowledge of physics and biology to build more intelligent monitoring solutions.
The Challenge - Invisible Containers
Let us consider Service X, which is composed of 3 short-lived containers. In the following figure, the graphs on the left plot their real performance over time, and on the right is the data that has been recorded by a traditional monitoring system:
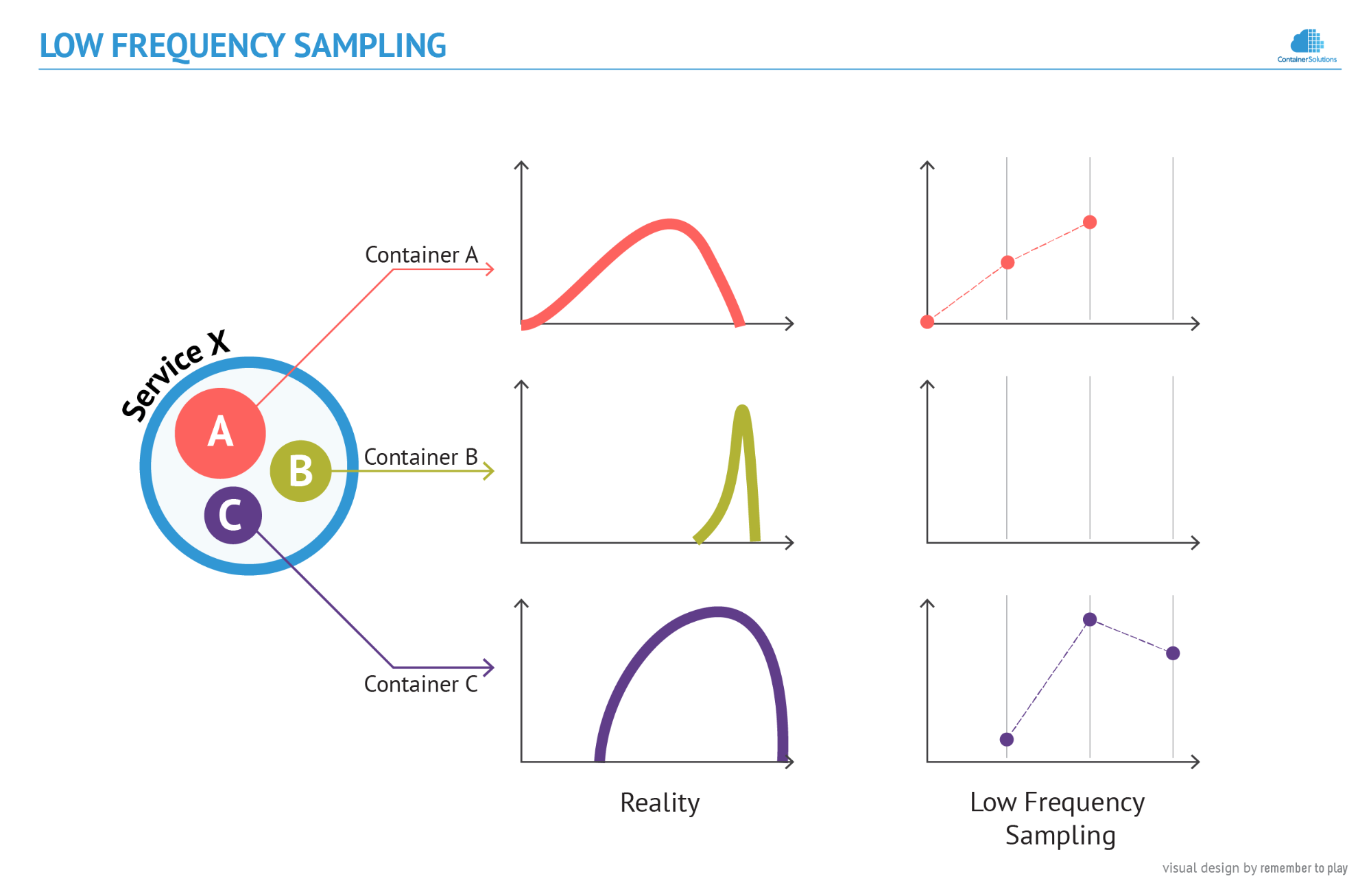
The typical frequency of sampling - every 1-10 minutes - which was suitable for monitoring physical servers and virtual machines, is clearly insufficient to monitor containers. Some of them, like Container B in this example, are so short lived that they go unnoticed. This means that if we use them to build a large micro-service system, a substantial part of it would remain unmonitored, un-monitorable, or both.
To fix this, we might think about increasing the frequency of sampling. The situation then looks like in the next figure:
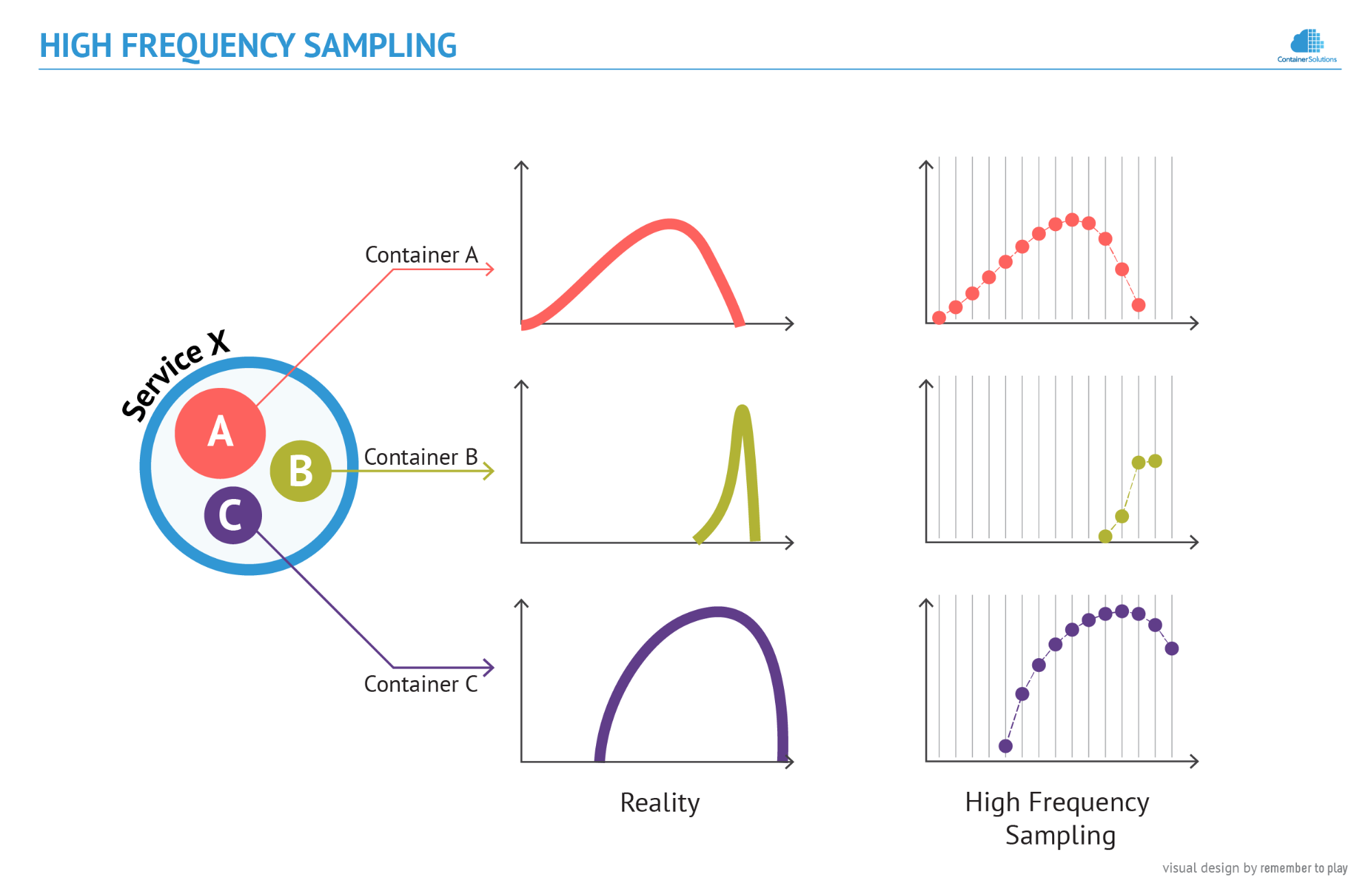
But what seems like a working solution - Container B is now visible - does not scale to production, particularly in environments where containers serve a single request/job and then disappear. Such ephemerality would require sampling at a frequency greater than 1 Hz (more than one sample per second), which would produce an enormous amount of data. I dare to say that the monitoring system would be more complex than the system it monitors.
The problem must be solved in a different way.
Evolution
A true solution can be found if we take a close look at evolutionary trends, and analyze where they point us to. That is the reason why in this section I am going to look at the history of monitoring solutions with a focus on their intelligence. More specifically, on contextual awareness - a notion which will be explained in the process.
Class 0 (Context-Less Monitoring)
I believe that a monitoring solution becomes functionally complete if it is able to perform two operations: collect information and alert if there is an anomaly.
If we accept this, then ping - a well-known administration utility - turns out to be the simplest functionally complete implementation that satisfies the criteria: it collects information on the round-trip time of ICMP packets sent to a given host and if the time exceeds a predefined threshold value (the timeout), it reports this as an anomaly.
This approach has a tendency to generate many false alarms, as an alert is sent every time the threshold is exceeded, which is not always an indication of a serious problem. In the past, however, various tools existed that relied solely on thresholds. I will refer to them as Class 0 solutions, as they began the history of monitoring solutions. Soon, though, more advanced solutions appeared.
Class 1 (Stateful Monitoring)
Nagios was one of the first representatives of the new class. The difference between it and the previous generation lied in the way it detected anomalies. More specifically, in the amount of contextual information that was used in the process.
First, let’s again have a look how Class 0 solutions like ping operate. The decision logic is in fact quite primitive: they look at the state of the infrastructure as it is at the moment of observation, then the information is compared with a threshold value to decide if the state is healthy or not. In other words, raw measurements without any additional context are sufficient for the monitoring systems to react, and the reaction is very deterministic.
Nagios was different. From the very beginning, it offered the mechanism of state flapping detection, which means that crossing the threshold value was not a sufficient reason anymore to trigger an alert. Instead, Nagios compared the current sample with the information on past values of the measurement, to ensure that this was truly an anomaly deserving attention. The memory of past samples provided historical context, a valuable source of information for all sorts of advanced anomaly detection algorithms. In more advanced implementations the memory could also be used for pattern detection, and if such patterns occurred (e.g. regular nightly backups that consume lots of resources) the decision logic could decide that something, which at first glance looked like an anomaly, was in fact harmless and therefore omit alerting operators.
The easiest way to explain the difference between Class 1 and Class 0 is to see what happens when measurements start to oscillate around a threshold value (so called state flapping). A Class 0 system reacts every time the threshold is exceeded, which floods operators with alerts. Class 1 system uses historical context to realize that the state is unstable, and only produces an aggregated alert from time to time.
The awareness of historical context results in more intelligent decisions and therefore more accurate alerting. The advantage is so significant that nowadays almost all market products work in a similar way: both traditional Ops tools (Icinga, Shinken, Zabbix, Sensu) and container-friendly products (Prometheus, New Relic, Dynatrace, Sysdig Cloud, Scout, DataDog). I will call this type of monitoring Stateful Monitoring, or simply Class 1 monitoring.
Class 2 (Syntactic Monitoring)
Class 1 monitoring solutions are more intelligent than Class 0 tools, but they both have an intrinsic limitation. Generally speaking, they do not understand the correlations between components. Such correlations exist if there are functional or structural dependencies between components, e.g. two containers competing for I/O bandwidth of a physical host that runs them. As a consequence, if the relationship is experiencing any problems (e.g. starvation), it is the operator’s responsibility to correlate the facts and draw their own conclusions. Naturally, the involvement of human operators dramatically affects the time of recovery.
This is not the case for the next class of monitoring solutions, which have just started appearing on the market. These not only understand the historical context like Class 1 solutions, but they also learn the syntactic (i.e. structural) context and actively use that knowledge. For instance, if related components degrade one after another (“domino effect”), instead of triggering a series of alerts, they generate only one.
The difference in the behavior of Class 2 and Class 1 systems can be observed when components have dependencies - for instance if a system consists of a database and many front ends that depend on it. A failure of the database immediately causes a Class 1 monitoring system to flood operators with alerts from all front ends affected. Class 2 instead realizes that the front ends depend on the same database, so most likely it is the failure of the database that is the root cause of the problem, and it generates only one alert.
The ability to correlate facts is a great step toward automated root cause analysis. This means that the operator of a Class 2 monitoring system is much less involved in both the workings of the systems and the decision making, as messages reach the operator much less frequently. And when they do, they carry more context. Effectively, a single operator with a Class 2 tool can do the work of several operators using older tools.
Monitoring And Physics
As of the moment of writing (December 2015), I am aware of only one Class 2 solution that is production ready. It is Ruxit, which appeared on the market quite recently (2014). As expected, it provides much deeper insight into the state of an infrastructure. Sometimes, before it triggers a single alert, its distributed AI algorithms analyze millions of samples to make sure that a phenomenon is a true anomaly. Yet, despite its sophistication, it still does not solve the main problem - how to monitor an infrastructure that changes rapidly.
For this, something more is needed, and the solution can be found if we look at the classes again, but this time from the perspective of physics. This is because all monitoring solutions make certain implicit assumptions about the reality they observe, and for each class the assumptions are slightly different. So in this section I will look again at the classes and physical models they implicitly use.
Context-Less Monitoring
As explained, Class 0 solutions look only at the current state of the observed objects. If we would like to find a physical analogy to containers observed in that way, the best might be atoms, as we imagine them to be solids that don’t change. Although we know thins not to be true, information collected in the moment of observation is sufficient to make certain decisions, for instance, classifying phenomena into acceptable or not, based on a threshold value. For atoms the measurement could relate to their size, mass, or energy; for containers - it is their performance.

Stateful Monitoring
The situation becomes more interesting if we look at the reality as it is perceived by Class 1 solutions. It is definitely more complex, as the solutions understand that the objects are not solid - their properties fluctuate. By recording the fluctuations (historical context), they build up knowledge, which allows them to improve their decision making process. Yet, it is interesting to notice that the fluctuations are not limited only to the observed object. They have yet another meaning.
I will explain this with an example. Imagine that we have a database and multiple front ends that depend on it. What can be observed is that shortly after the database experiences performance problems, the performance of the front ends also drops, and finally, a few moments later, users start to experience a decrease in performance as well.
So the fluctuation is not just a property of the monitored object. It is a wave that propagates through space and, over time, changes the performance of the objects it meets along its way. So if we were to find a physical analogy for the reality as seen by Stateful Monitoring, it is a space of radiating objects. This sounds abstract, but it takes us closer to finding a solution to monitoring ephemeral containers.
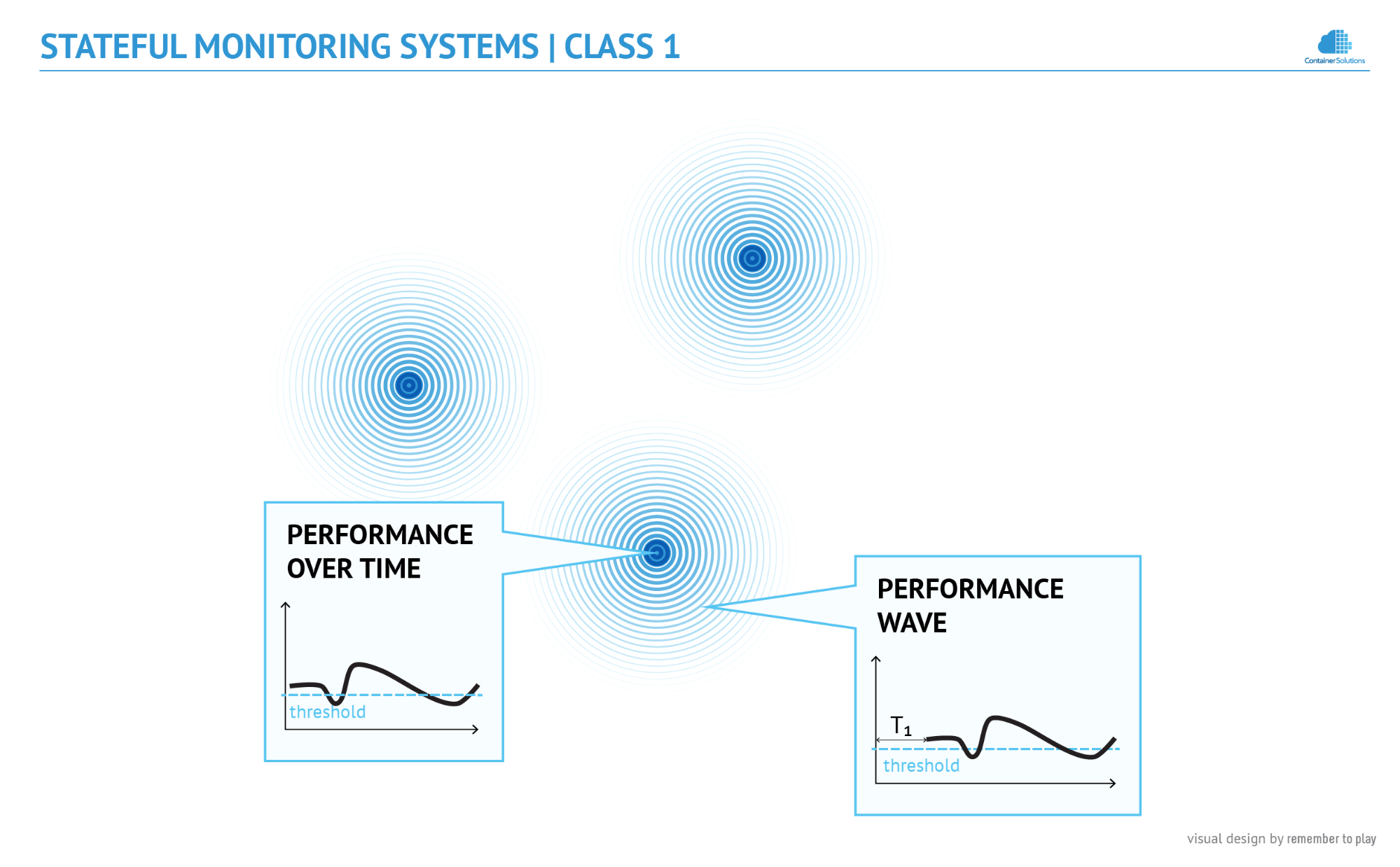
Syntactic Monitoring
Shifting focus from solids to waves improved the decision process for Class 1 solutions, but the real use of the knowledge is made by Syntactic Monitoring, as it collects information on how the performance of objects fluctuates, while additionally having knowledge of the structure of systems. So if we translate this to the language of physics, such a system effectively knows how the waves propagate and where they meet.
Understanding the physical analogy provides a new perspective. The effective performance of every container can be seen as the result of its own performance influenced by the performance of its dependencies. So if in the previous example a front end would depend on two databases, its effective performance would probably be correlated with their performance. The correlations could be strong or weak, depending on how strong the dependencies currently are, but the fact that they exist is already valuable information, which can be used in practice.
The algorithm is simple. If there is a drop in performance, it suffices to check if there has been (note the time shift) a corresponding decrease in any of its dependencies - if so, we know the culprit. If not, the drop must have been caused by the object itself. The figure below shows how the decrease of performance of Container C was correlated with one of its dependencies - Container B.
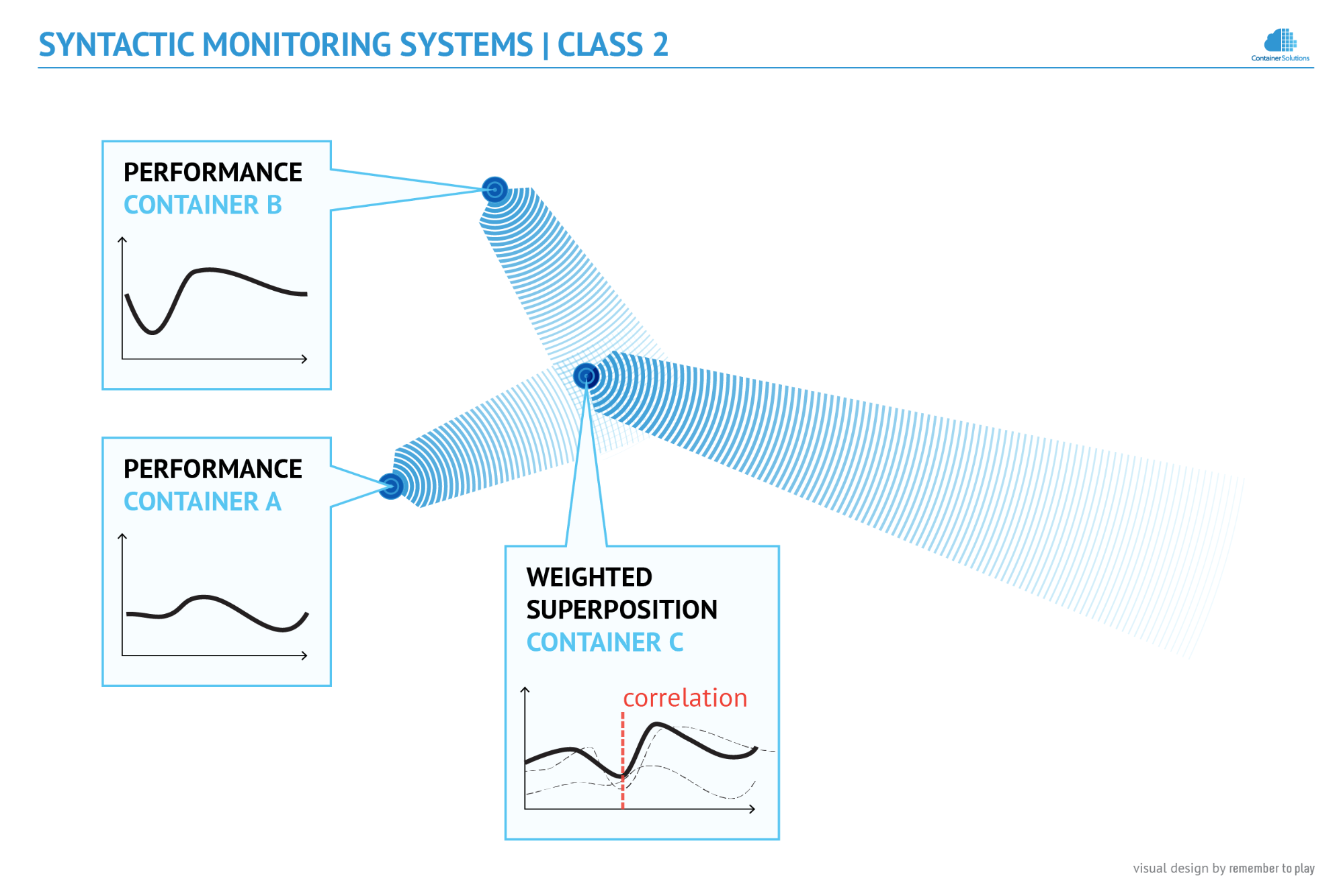
This illustration is also a good representation of the reality as it is seen by Syntactic Monitoring - it is the space of objects, which are sensitive to the radiation of objects close to them (the dependencies). As the monitoring system knows the relative position of objects (the connections between containers), it can track wave interferences in order to analyze the correlation between wave components and their superposition. This simple rule is the basis for the root cause analysis performed by Class 2 solutions.
Monitoring - The Next Generation
The principle used in Syntactic Monitoring is powerful, but does not scale. In dense grids like microservice architectures, which are tightly interconnected and mutually dependent, the number of interferences is so large that it would be computationally challenging if we were to track each pair of related components. This severely limits the ability to understand what happens in such a system.
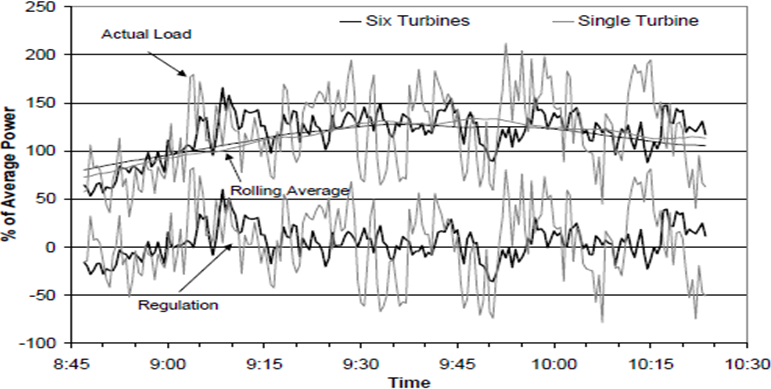
Luckily, we already have many years of experience with power grids, which are similarly dense, and we can likely learn some lessons from those systems. Let us have a look at the sources of renewable energy. For instance, the next figure shows how wind turbines behave when clustered into a group of six (from Grid-Connected Wind Park with Combined Use of Battery and EDLC Energy Storages by Guohong Wu, Yutaka Yoshida and Tamotsu Minakawa):
and the following figure illustrates the behavior of solar panels clustered into larger and larger solar plants (from Variability of Renewable Energy Sources by National Renewable Energy Laboratory):
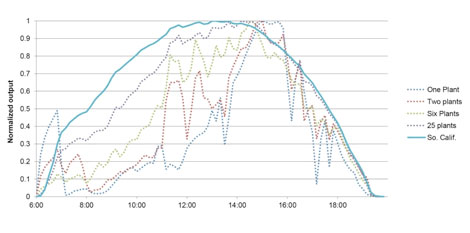
The data provides some clues as to how software systems could be monitored despite the ephemerality of containers.
First, unstable sources of power deliver quite stable output if connected into a group. Their small fluctuations simply cancel each other out. This leads to conclusion that the addition (superposition) of unstable waves clears the noise from individual wave components. Indeed, noise reduction is a well-known property of superposition, and it is commonly used by many imaging technologies, both human-made (e.g. arrays of telescopes), and biological (e.g. compound eyes), in order to provide high-quality images from low-quality sensors. So if we look at wind turbines and solar panels as sensors, the superposition of signals they produce (i.e. output power) provides a high-quality image of the phenomena they observe - in this case the wind and the solar radiation over Southern California. Similarly, we might expect that if we superpose performance readings coming from low-quality components such as ephemeral containers, the result will provide high-quality information on the performance of the service they collectively provide.
The next observation is that the larger the group of components is, the slower their collective output changes. And as the chance of a rapid change is small, this means that we don’t need to check the state very often to understand it sufficiently well. In biology the phenomenon is also well known. As the body size of an animal grows, its maneuverability decreases (due to inertia), so there is no need for predators to observe large prey with high temporal resolution:
“[...] owing to the laws of physics, larger animals physically respond less quickly to a stimulus. Hence we expect selection against costly investment in sensory systems with unnecessarily high temporal resolution in large animals, as information on such timescales can no longer be utilized effectively”. [1] (Healy et al., 2013)
In our context the conclusion is that if the group of containers is large enough, checking its state with low frequency should be sufficient to understand the state of the service it provides. And as low frequency monitoring is cheaper, this is exactly what we are looking for to solve our original problem.
Taking all of this into account, I think that the final conclusion is that the solution to the problem of ephemeral containers is a new monitoring system that shifts focus from individual containers to the collective behaviour of a group. So similarly to physical reality, where atoms change too fast for us to observe, we can shift focus to groups of them - particles. If they still change too fast, we can can shift focus to higher levels of abstraction like cells. The process can continue until we find a level where movements happen at a speed comparable to the speed of the observer’s reactions. Once the level is reached, then even low frequency sampling (low temporal resolution) is sufficient to follow interactions between such compounds.
So, again if I were to find a physical analogy to the reality as it is seen by this new type of monitoring, it would be the realm of bigger and bigger compounds that interfere with each other. This means that once we learn to calculate the collective behavior (superposition) of a group, then we can apply the same technologies as Syntactic Monitoring tools use today at the level of individual containers to understand interactions in the observed system.
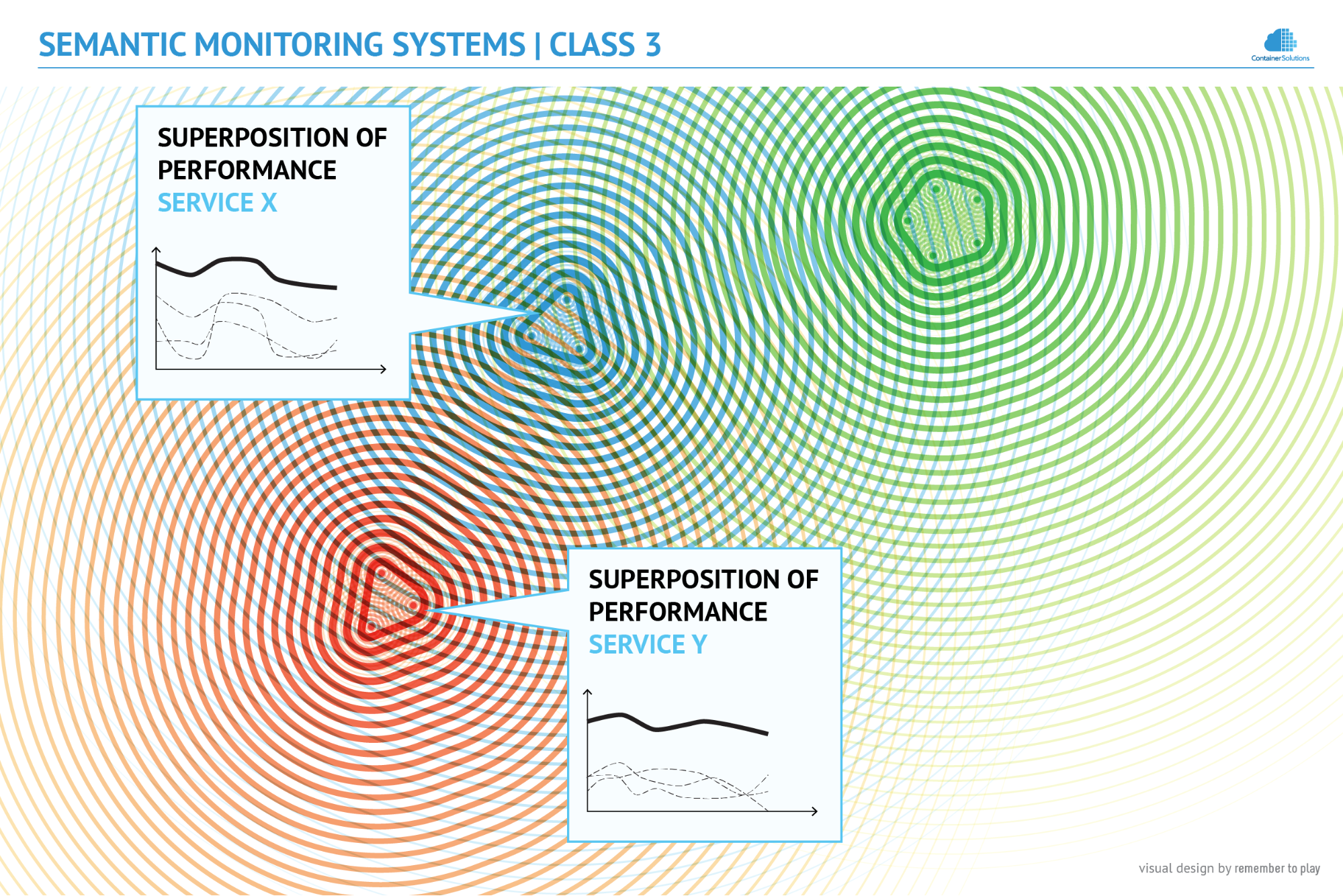
Class 3 (Semantic Monitoring)
The new monitoring system clearly needs to be more intelligent than previous generations, as it needs to calculate the collective impact of containers onto their environment. This means that on top of historical and syntactic context, it needs to be aware of semantic context - the functional role (meaning) of every container in order to group them in a sensible way. At this new level of monitoring (Semantic Monitoring) the collective aspects, such as the consistency of information stored and the resilience of structure, are more important than the health of individual containers.
Class 3 solutions understand that the given group of containers works collectively to achieve a specific goal. That’s why if a distributed database is unstable (e.g. Elasticsearch is in yellow state - not enough replicas), Class 3 immediately alerts that business continuity is endangered, whereas Class 2 believes that everything works fine as long all endpoints respond correctly. And the opposite: if a container has crashed, but Class 3 knows that it will be immediately replaced, it does not trigger any alert, whereas Class 2 does, as it does not have the knowledge that the component is part of a larger whole.
Given the original example of 3 containers that provide Service X, this is how Semantic Monitoring would work:
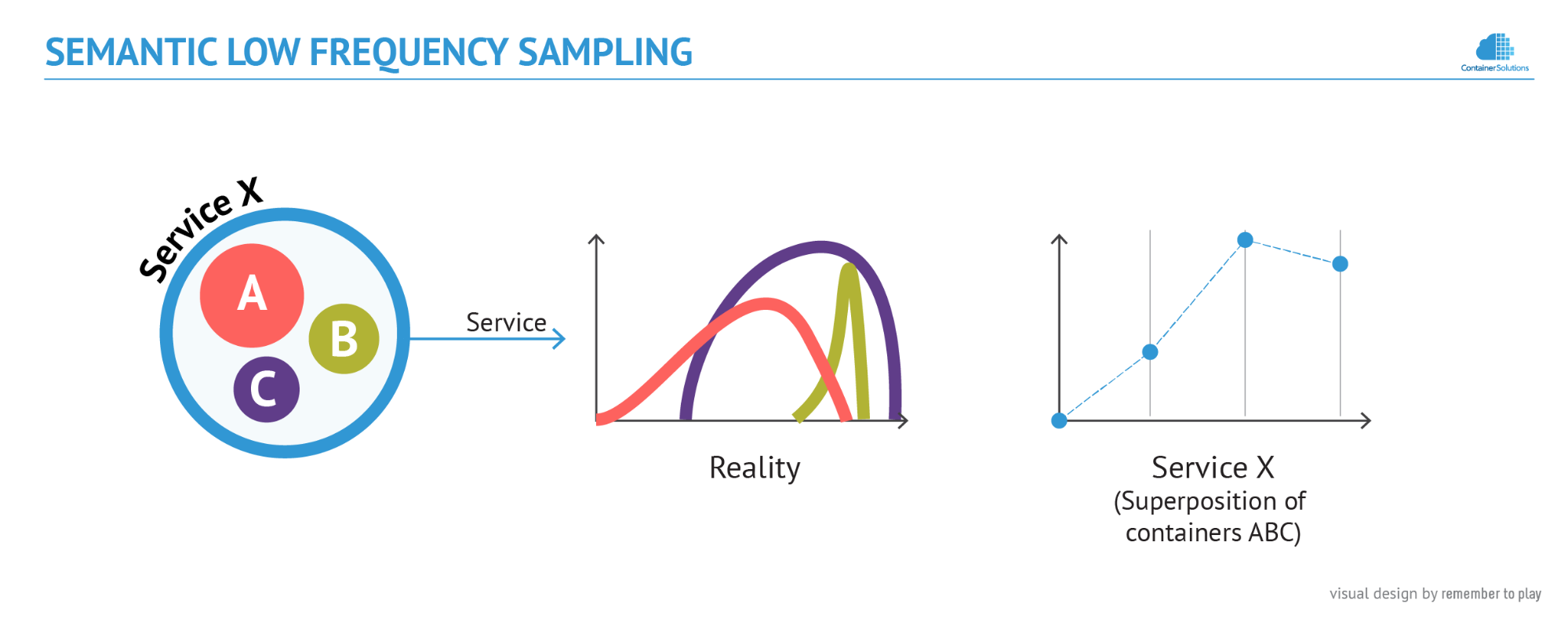
Every time the monitoring system is about to take a sample of the performance of the service, it checks which are the containers that provide it. Then it measures their respective performance and sums it up (the assumption here is that the service scales linearly).
This way, Class 3 solutions would collect information on the overall performance of the service, and later use it for calculating its collective influence on another group of containers that provide a different service.
Conclusion
The DevOps movement appeared as a reaction to the problem of miscommunication between developers and operators, as it had been noticed that when a software system passes from development to production, the large amount of information, related mainly to its structure and the role of its components, was lost.
This research showed that the loss of the contextual information has yet another unexpected consequence - it blocks monitoring solutions from becoming more intelligent, because while the structure (i.e. syntax) of systems can be partially reverse-engineered through network discovery, recovering the role of system’s components (i.e. semantics) in an automated way is nearly impossible.
Fortunately, as an industry we have started to face the problem. On one side we have vendors like Ruxit, who build complex processing logic around graph models of systems. On the other side, developers are learning to model systems as graphs (by using tools like HashiCorp’s Terraform). I believe that the historic picture below is a good metaphor of the situation we have now, and hopefully soon the initiatives from both worlds will meet and agree upon a common domain-specific language (DSL) for expressing both structure (syntax) and the meaning (semantics) of systems.

The Harbour Bridge in Sydney - the collection of National Library of Australia
Once this happens, systems of any complexity will progress from development to production without any loss of information and with no need for having IT operations involved in the process (more on this trend in Dev and Ops in the Time of Clouds). That effectively means that there will be no need for DevOps anymore.
Eventually this will be the beginning of a new generation of cloud computing (more on its features in From Microservices To Artificial Intelligence Operating System).
Q&A (Update 2016-09-08)
Please check the Comments on Semantic Monitoring and Scheduling blog post for more information on Semantic Monitoring.
References
[1] Kevin Healy, Luke McNally, Graeme D. Ruxton, Natalie Cooper, Andrew L. Jackson - Metabolic rate and body size are linked with perception of temporal information (2013)
Under a Creative Commons license
Graphics designed by remember to play