
Docker 1.10 came out a few days ago and brought with it Swarm 1.1.0.
The most notable (still experimental) feature in this release is the native rescheduling of containers on failures of individual Swarm nodes.
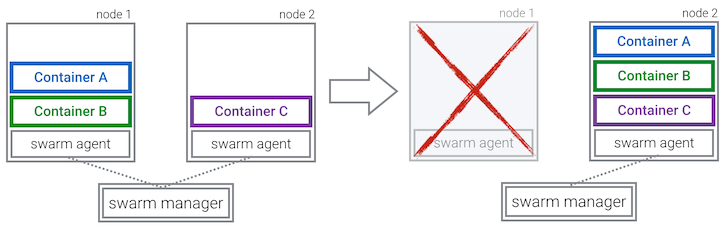
Some people I talked to were a bit surprised that such a seemingly crucial feature was missing in Swarm until now, as Swarm was declared production ready last year and solutions such as Kubernetes and Marathon supported this all along.
Certainly, one reason is that the Docker Engine has supported the `--restart` flag for a while, which supports various policies to automatically restart crashing containers. In my own experience, your software running inside in the container fails far more often than a whole node going down, so this does at least cover a common class of service failures.
But extending this concept to also deal with node failures is not straightforward, which is why I think it took a while - keep in mind that Docker Swarm is a relatively young project compared to its competitors.
Therefore, until now the recommendation for production setups was to use an external tool to monitor if the desired number of instances for your service deviates from the actual number running, and take corrective action in that case (either automatically or by good old alerting on-call staff)
Which brings us to the first difficulty:
Instance count guarantees
Which component should decide if a container is broken and must be rescheduled: Swarm or the Docker Engine locally on a node? To keep the existing restart policies reliable, Swarm only deals with complete node failures and leaves individual container crashes to the Docker Engine - so restart policies still work if the Swarm manager goes down.
One downside of this is, that there are now two components responsible for the health of your application. This makes it more difficult to give guarantees about how many instances of your image are running: A crashing Swarm agent on one node can cause duplicates of all its running containers to be scheduled on another node.
Be aware, that this is a common problem with schedulers, just a bit more pronounced when you combine restart policies with rescheduling. The reason is, that during temporary network partitions, it may happen that the scheduler thinks a node is down and decides to reschedule all its containers, even if they are actually running fine.
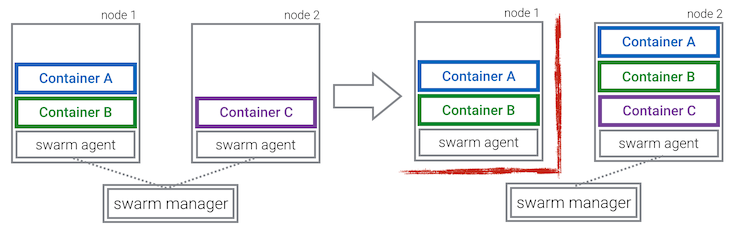
To keep things simple, the current implementation does not deal with this issue at all. It only removes any duplicate containers as soon as the Swarm agent of the broken node reconnects to the Swarm master.
Of course the issue was discussed in the respective tickets, so we might see work on that in the future.
Just keep in mind that with rescheduling enabled, you can't guarantee that only exactly one instance of an image is running - which you might depend on for specific use cases.
The next challenge is...
Networking
When a container gets rescheduled, it will by default get a new IP address. If this poses a problem to you, you can in theory use Docker's multi-host networking feature (using `--net` and `--ip` flags). I did a quick experiment testing this (with and without `--ip`), but the rescheduled container always lacked the additional overlay network interface that its predecessor had. So at the time of this writing, it seems that you can't use rescheduling together with multi-host networking, and you have to resort to more classical service discovery mechanisms involving port mapping.
Finally, the maybe hardest nut to crack is...
Volumes
A rescheduled container will obviously lose any data it had access to, when it had volumes mounted on the previous host. To avoid this from happening, you can use volume plugins like Flocker.
As multi-host networking did not work yet, I haven't tried volume plugins in combination with rescheduling - please share your results in the comments if you did try it.
How to use rescheduling
As of this writing, there is only one rescheduling policy: `on-node-failure` - which does what you'd expect.
To start a container with rescheduling enabled, pass the policy as environment variable or label, e.g.:
docker run -d -l 'com.docker.swarm.reschedule-policy=["on-node-failure"]' nginx
or
docker run -d --env="reschedule=on-node-failure" nginx
As this is an experimental feature, you need to launch the Swarm manager and agents with the '-experimental' flag, e.g.
docker run --name swarm-agent-master swarm -experimental manage ...
docker run --name swarm-agent swarm -experimental join ...
Closing thoughts
With version 1.1, Docker Swarm is becoming an interesting option for lightweight container infrastructures, as you don't need any additional plumbing anymore to deploy your services in a fault tolerant way.
But of course, there is still a lot of work ahead:
- While rescheduling helps for hard failures, it does not yet rebalance your Swarm cluster when new nodes become available. This can be desirable if you defined soft filter expressions to optimise your setup for availability or performance (e.g. keeping containers that interact a lot on the same node).
- Also maintenance scenarios are currently not covered, like Mesos' resource draining which triggers the rescheduling of workloads from nodes that are marked for maintenance.
Still, try it out for yourself if you are not afraid of experimental features.