
Implementing Continuous Delivery[1] at enterprise scale is a major challenge. As every company has to innovate their software delivery methods, we need to allow individual teams to learn and improve their own delivery pipeline. This is especially true in the Cloud Native world, where many best practices are still emerging. However, giving teams flexibility to experiment needs to be balanced with security and compliance requirements. In this post, I will explore how we successfully employed the GitOps architecture pattern to find a good balance between flexibility and security at a large enterprise customer of Container Solutions.
Context
This article focuses on enterprise companies with tens or hundreds of development teams. I will also assume Kubernetes as the application runtime platform. While the principles outlined here can be applied in other platforms, Kubernetes really shines in making Continuous Delivery easier to implement, and this simplification helps with making the article more focused. Finally, this will be a technical article, but not a very deep one. I will explain the solution on the level of boxes and arrows, and maybe follow up with a more detailed technical description later.
Flexibility for enabling innovation
If every team at a large company is locked into the same development process, it is very hard to innovate. Both because the innovation needs to start top down, and also because it’s a very risky business: any new method is intended to completely replace the old one. As changing work processes is one of the hardest goals to achieve in a complex organization, it is both imperative to start small, and that there is fertile ground to begin on.
Here are two examples of different processes a team might employ. The first is heavy on manual work and approval, while the second is the process of a more mature team, relying on test automation and doing away with management approvals. They show how it would be folly for any organization to codify a one-size-fits-all development process for tens or hundreds of teams. Each team will have their own unique circumstances and path to innovate on how they deliver their applications.

Continuous Delivery process with manual QA approval

Continuous Delivery process with fully automated testing
Compliance and Security
Let’s take a closer look at our compliance and security requirements! Enterprise companies not only have strict requirements of their own but also can be subject to government regulations.
Here is a common list of compliance & security requirements which apply to software delivery:
- Access control - Control who is allowed to deploy what on which environment.
- Audit trail - Have a record of all changes to the environments, with data about who changed what and why.
- Approval process - Changes to certain environments need approval from authorised personnel to proceed.
As the Continuous Delivery process modifies critical software environments it has an important role to play in satisfying these three requirements. If the development team is not allowed to touch the production environment, neither can the CD Platform unless it does the authorisation on who can perform the deployment action. This is just one example. Let’s dive into the difficulties with creating a platform that is flexible, secure and compliant.
Deploying from Jenkins
For starters let’s take a look at a naive implementation of a Continuous Delivery Pipeline using the popular Jenkins Pipeline plugin. This is the simple approach to implementing a pipeline, which is sufficient for many environments, but not for our use-case.
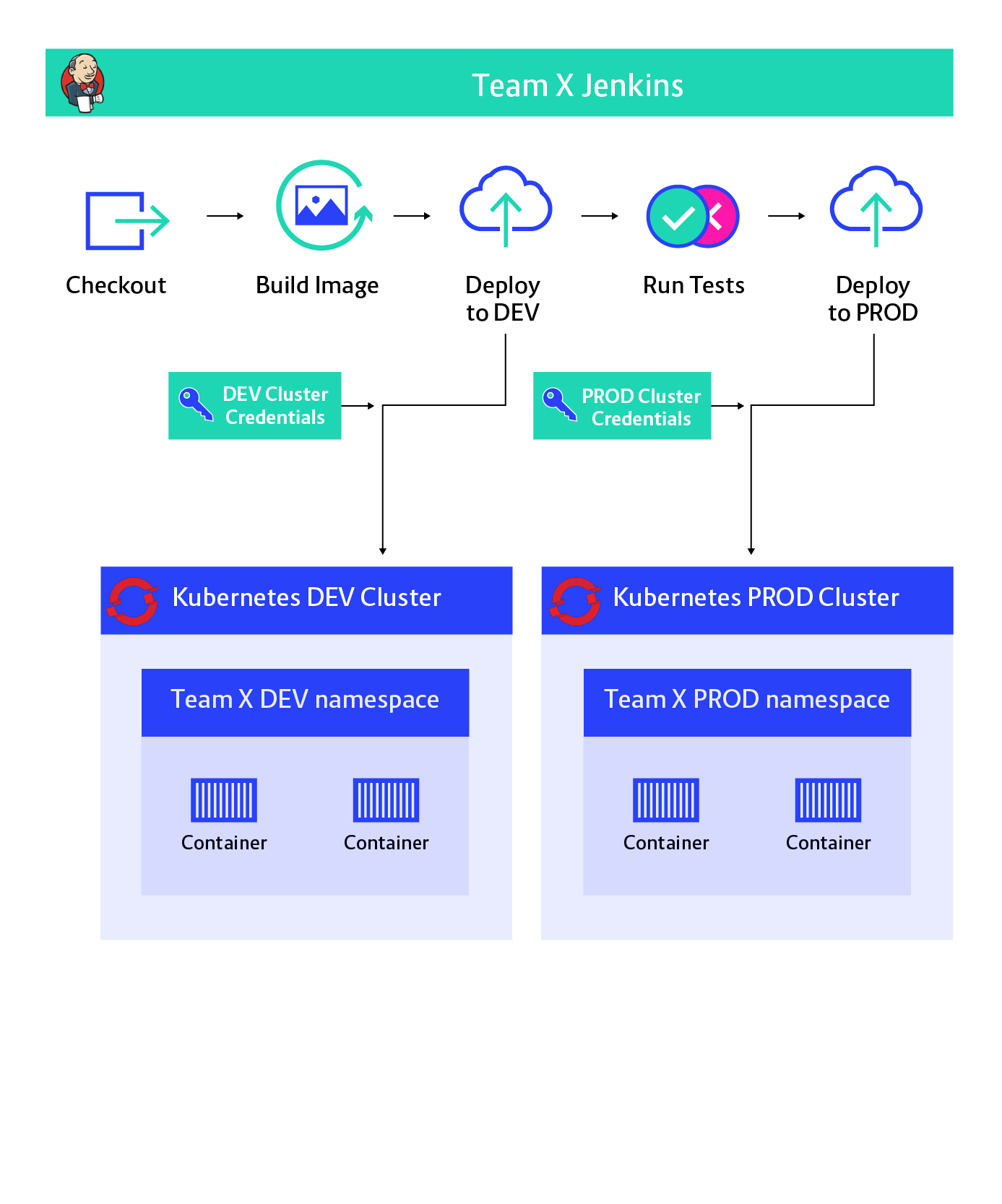
This would build a Docker image and deploy it to Kubernetes, which is great. So what’s the issue here?
First of all, Jenkins has to hold the credentials for the Kubernetes cluster (including the production cluster). This means admin access to Jenkins must be reduced to the people with access to production, limiting options for the development team to choose their tools.
Secondly, anyone with access to the Jenkinsfile can modify the pipeline and just print the production credentials or use them to execute commands against the production cluster. This means we can’t even have the development team edit the Jenkinsfile. This is a severe limitation as the pipeline can vary team by team and even between different services delivered by the same team, as I mentioned in the chapter about flexibility.
In summary, we either store credentials in Jenkins or severely limit the flexibility of development teams using it. Clearly, this is not what we are aiming for, but it’s important to understand why the straightforward approach is not sufficient.
GitOps
So we have the conflicting goals of implementing a CI/CD system that is secure, compliant, but flexible at the same time. How can we achieve this?
We can start by separating the delivery process from the deployment process. This way cluster credentials can be removed from the Jenkins pipeline executing the delivery process. The deployment process can reside in another Jenkins or some other tool - I’ll stick to Jenkins to make things simple.
With this new separation of concerns, we need a way for the delivery process to inform the deployment process, that it needs to deploy a certain version of the application or make some other change to the environment (e.g.: adding a new environment variable). An amazingly powerful yet simple way to achieve this is to use Git as a mediator between the two processes. We can create a Git repo, which contains all the information about our environment and have the deployment process listen to changes in this repo.
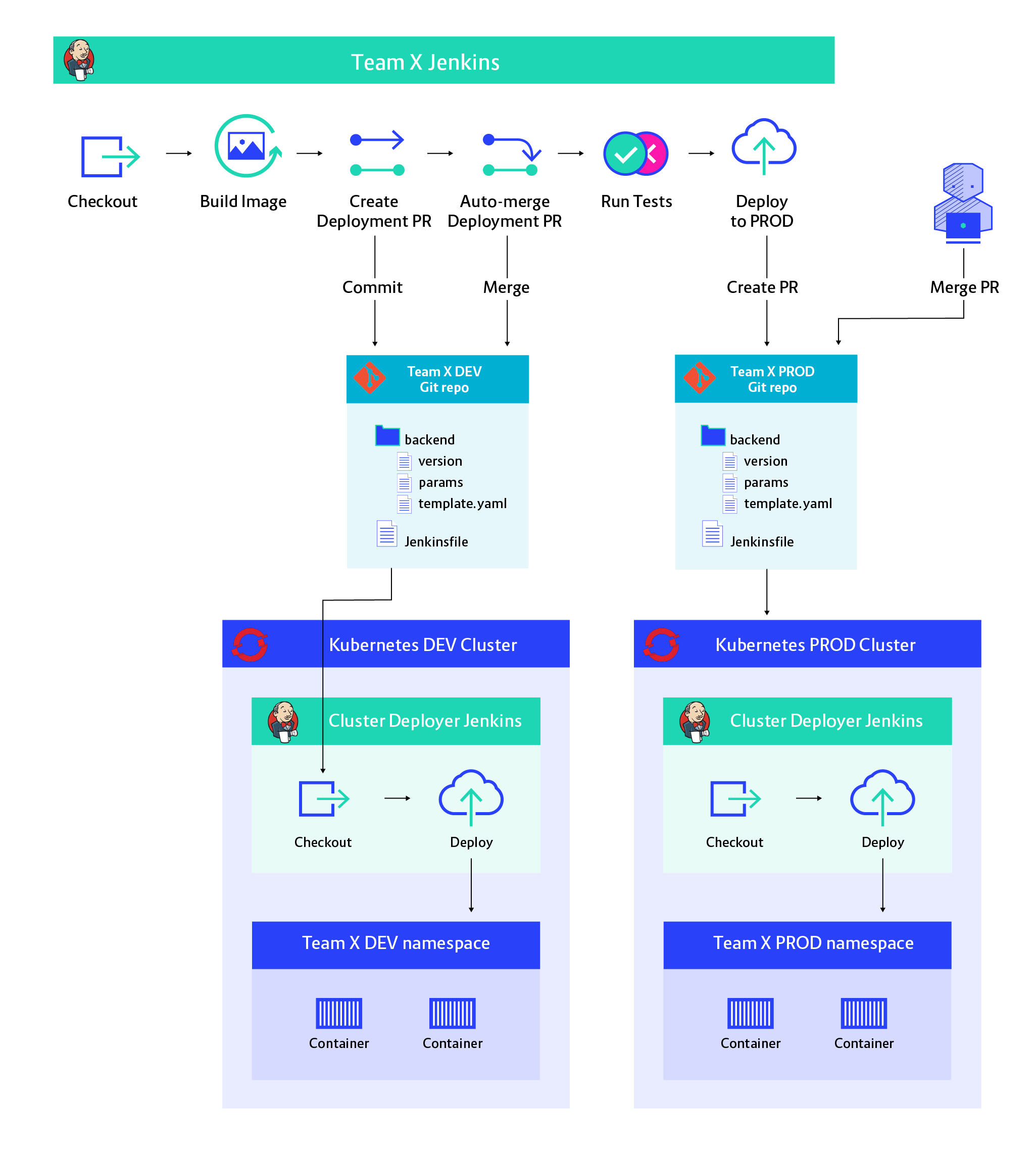
Continuous Delivery architecture with GitOps
Notice how a Git repository is now separating our deployment process from the delivery process. From the delivery process's perspective, deployment means making a commit to the Git repository in the middle. This way delivery process never has to touch the Kubernetes cluster. In the meanwhile, the deployment process can be started whenever a change is merged into the Git repository.
GitOps is a pattern which has been coined recently by Alexis Richardson from Weaveworks and has gained a lot in popularity[2]. Infrastructure-as-code is an idea which has been with us for a few years now, ever since the invention of public clouds where every resource can be defined as code. GitOps is a logical extension of that idea to applications running in Kubernetes. Kubernetes's deployment mechanism allows us to fully describe our applications as text files, which we can store in Git.
Let’s see how GitOps helps us with our three compliance headaches:
- Access control: Only people who get write access to an environment’s configuration Git repo are able to deploy to that environment.
- Approval process: For sensitive environments, we can allow the development team’s Jenkins to create a Pull Request (PR), but only allow authorised personnel to merge it. This creates a very nice approval process with little implementation overhead.
- Audit: Because Git is a version control system it is naturally great at keeping track of changes. Each Git commit identifies the person who made the change and has a message describing the change.
The overall result of introducing GitOps is creating a secure process which can be proven to adhere to compliance requirements. If the user management on the operations repositories is configured correctly - only authorised personnel can merge PRs. There is now no way for any member of the development team to modify the production environment without getting approval from operations.
Did we just reinvent infrastructure as code?
The idea of infrastructure as code has not arrived with GitOps. Tools like CloudFormation and Terraform are popular and help to manage infrastructure as code. These tools are used for declaring infrastructure while Kubernetes is focused on running application components (microservices) as containers. In these containers the ever-changing application code lives - this is the point where we need to deliver continuously. We like to handle these fast-paced releases using our traditional CI tools, as the CD process is clearly a continuation of the CI process.
Conclusion
Decoupling the delivery pipeline from the deployment process using Git in the middle is an efficient way to both achieve the goals of continuous delivery under the restrictions of compliance and a high-security environment. It frees us from the task of having to search for that perfect tool, one flexible enough to handle our release and deployment processes while also having advanced user management, authorisation, and auditing capabilities. While the complexity increases quite a lot with a decoupled solution, we get high returns by being able to pick and choose different tools for the delivery pipeline and also for executing deployments.
In an enterprise environment, this freedom has huge consequences - with smaller pieces to change one at a time, managing migrations to better tools in the future becomes much easier.
Notes
[1] https://continuousdelivery.com/
[2] https://www.weave.works/blog/what-is-gitops-really
Enjoy our content so far? Please make sure to subscribe to our WTF is Cloud Native newsletter:
