

ImageWolf now has support for Kubernetes! We even made a video (see below). If you want to see the code though, you can find it in its normal place.
TLDR; we used BitTorrent to speed up Kubernetes deployments https://github.com/ContainerSolutions/ImageWolf
That’s great! but what is it? I’m glad you asked. Essentially, it’s a service that aims to alleviate bottlenecks when deploying or updating a new application over a cluster by leveraging the distributed BitTorrent protocol. That’s quite a mouthful, so let’s unpack it.
Let’s start by looking at the problem ImageWolf has been created to solve. Imagine you have a legion of servers running your application (under Kubernetes, Docker Swarm, etc.) A developer creates a cool new feature and wants to show it off to the world! Let’s run through what they would do. So the developer commits their code and triggers their continuous integration pipeline. As anyone who has played with ci/cd knows, when that fateful push happens, The deployment process begins.
All this sounds pretty mundane so far… But what happens now? In a standard Kubernetes rolling update (more on this below) All the nodes need to grab the image from the registry, decompress it and load the local store. All 1000 of them, or all 3 of them.
Now we have a problem. There are suddenly hundreds (or thousands) of nodes attempting to pull down the same image. Using a Registry as a pull through cache can reduce the load time, but only when pulling from the Docker hub (see Gotcha’s). One could use your pull through cache to additionally serve private images, but then one loses the benefit of proximity to nodes. One of the aims of a cache is to move data that is more likely to be used closer to the client, in this case the Kubernetes nodes.
Enter ImageWolf stage left
So how does ImageWolf solve this problem? Let’s go back to the statement I made earlier:
It’s a service…
A DaemonSet in the context of Kubernetes means a program which runs on every node. A node is generally a single server (VM or dedicated box).
…that aims to alleviate bottlenecks…
I want to take a moment here to describe the issue in a little more detail. When updating a currently running application, Kubernetes has several different deployment strategies. These strategies define how a new version of the application is rolled out to the cluster. Currently there are only two deployment strategies, namely ‘Recreate ’ and ‘Rolling Update’.
The ‘Recreate Deployment’ strategy is pretty simple, essentially kill all currently running pods, then start new pods. At this point, every node in the cluster is going to start trying to pull down the new image from the registry. This is a pretty clear place where the registry will suffer from high load. The second strategy ‘Rolling Update’ is a little more subtle. The logic behind the strategy is that it will slowly take down old pods while replacing them with new pods. The first thing I thought when I heard this was, “does it create excess pods, or does it kill a pod before replacing it?” Well the answer to that is both, or more accurately, you can choose. There is the option to specify the maximum number of unavailable pods, or the maximum ‘surge’ pods allowed. Now we come to how images are pulled during an update. Put simply, the image isn’t pulled until the node is ready to schedule the updated. This means that our registry shouldn’t suffer from the instantaneous high load issues that came up in the other deployment schedule. What does still happen though is more of a death by a thousand cuts. Pulling an image from the registry can take up to 15 seconds before it is ready to be brought online. This can have huge ramifications when rolling out to many nodes. If the image is already on the node then the load time of the new version under a second again.
…when deploying (or updating) a new application over a cluster by leveraging the distributed BitTorrent protocol.
ImageWolf will listen to event callbacks from registries regarding newly pushed or updated images. ImageWolf will then download the image and distribute it to all nodes using the BitTorrent protocol. Now, when we trigger the deploy, every server already has a local copy of the image (or will fall back to the registry if it doesn’t yet). This can lead to a large reduction in start-up time (26x in casual testing).
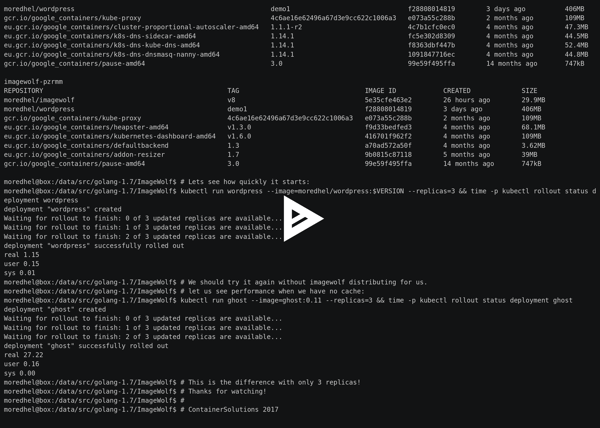
I have some numbers with me (not very scientific, granted, but pretty good), of running this on Kubernetes the difference in startup performance is pretty pronounced. Below, we see starting a Kubernetes Deployment after ImageWolf has already distributed the image to the nodes:
moredhel@box:/data/src/golang-1.7/ImageWolf$ kubectl run wordpress --image=moredhel/wordpress:$VERSION --replicas=3 \
&& time -p kubectl rollout status deployment wordpress
deployment "wordpress" created
Waiting for rollout to finish: 0 of 3 updated replicas are available...
Waiting for rollout to finish: 1 of 3 updated replicas are available...
Waiting for rollout to finish: 2 of 3 updated replicas are available...
deployment "wordpress" successfully rolled out
real 1.15
user 0.15
sys 0.01
1.15 seconds! pretty good!
Let’s compare this to a rollout of a similar sized image when all nodes need to pull from the registry:
moredhel@box:/data/src/golang-1.7/ImageWolf$ kubectl run ghost --image=ghost:0.11 --replicas=3 \
&& time -p kubectl rollout status deployment ghost deployment "ghost" created
Waiting for rollout to finish: 0 of 3 updated replicas are available...
Waiting for rollout to finish: 1 of 3 updated replicas are available...
Waiting for rollout to finish: 2 of 3 updated replicas are available...
deployment "ghost" successfully rolled out
real 27.22
user 0.16
sys 0.00
That is a pretty big number! And we’re only deploying to 3 nodes. This will just get worse as more nodes are added to the cluster, Give it a try! Be amazed! Come back when you break it (because we want to make it better!).