

In the last two months, I've worked together with Chef to evaluate Habitat from a cloud native developer perspective. This is the second blog in a series of three where I'll share my experiences. The first blog is about the build system, and the last will be about how to create a High Available Redis cluster with automatic failover on top of kubernetes.
TL;WR: Setting up habitat supervisors on top of K8s is not trivial. I solved this by using Statefulsets to create a stable endpoint for nodes to join. Check out the instructions on GitHub to run it yourself.
Habitat consists of two parts: a build system and a runtime supervisor that can react to changes during runtime. The previous blog covered the build system, in this blog I’ll show how these runtime supervisors can be run on top of kubernetes.
What are supervisors
Habitat supervisors provide runtime automation that travels with your application.
When you start multiple instances of the same application, you can instruct those supervisors to communicate with each other by gossiping. This is close to how Consul / Serf work as well.
The first application instance is started with hab sup start $YOUR_PKG, the following instances should be pointed to the IP address of the first, to be able to join the gossiping. The command to start them is hab sup start $YOUR_PKG --peer $IP_ADDR_OF_ANY_OTHER_STARTED_NODE.
Supervisors allow users to change the configuration of the deployed applications without issue redeploying them. In the context of running Habitat on top of kubernetes, this feels a bit like ssh-ing into a machine to change a configuration file, that is managed by Chef. On the other hand, this opens up some more opportunities to automate these configuration settings even more, as we’ll see next.
An interesting feature is that one service managed by a supervisor can observe another service, which potentially runs on the other side of the globe. When the observed service changes, the observer is notified of this change.
A change in the observed service is either a modification to it’s configuration, or if one of the instances of that service started, stopped or crashed. The observing supervisor can then regenerate the configuration of the application it manages, and execute an optional hook that allows you to implement custom logic.
This enables the application to manage service discovery by itself; it can simply bind to e.g. the caching service, and update its configuration file on any change in available nodes. In the context of Kubernetes, I think that this is a useful concept for tightly coupled applications, such as a microservice that has a backing database that only this microservice can access.
Inter-microservice communication should be decoupled as much as possible.
Aside from enabling runtime configuration and observation of services, the supervisors also support setting up several forms of topologies, such as initiator+rest and leader/follower. In the next blog, I’ll show how we can use supervisors on kubernetes to have a uniform HA redis cluster, that will offer two services, the redis-master and redis-slave services.
The problem with habitat + kubernetes
Let's say that we want to run a high available redis cluster. The best practise in kubernetes is to deploy an application via a Deployment. Once we created this Deployment in kubernetes, it will programatically create a ReplicaSet, which in turn will create Pods. The Habitat supervisors in the pods will perform leader election, after which somehow it should apply the correct kubernetes labels to those pods, such that the pod that won the election will be selected by the redis-master service, and the other two pods by the redis-slave service.
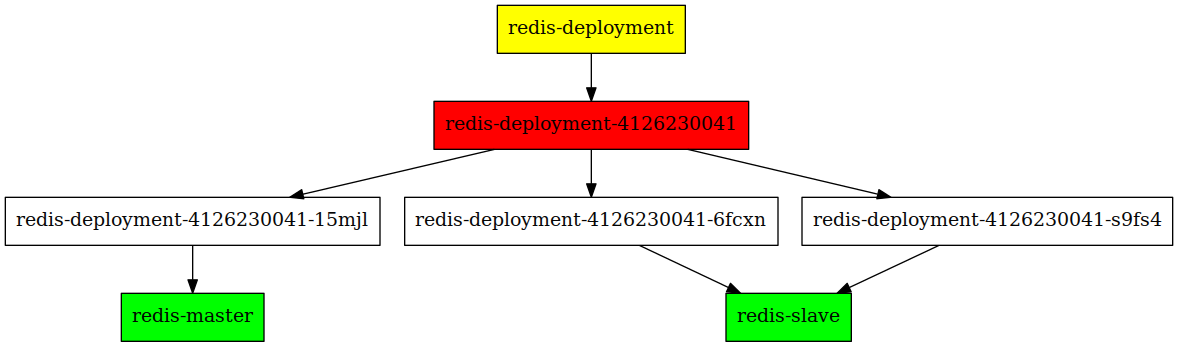
Ideal situation
Setting this up on kubernetes can be tricky. Remember that Habitat requires that the initial node is started without the --peer option. If you'd use a ReplicaSet, as is done by the Deployment we created, you can only create identical pods, and therefore either all of them will have the --peer option, or none of them will. In the first case, nothing will happen because the supervisor will try to join the peer node before allowing other nodes to join it, and in the latter none will ever join, and therefore they will not be linked to the redis-master and redis-slave services.
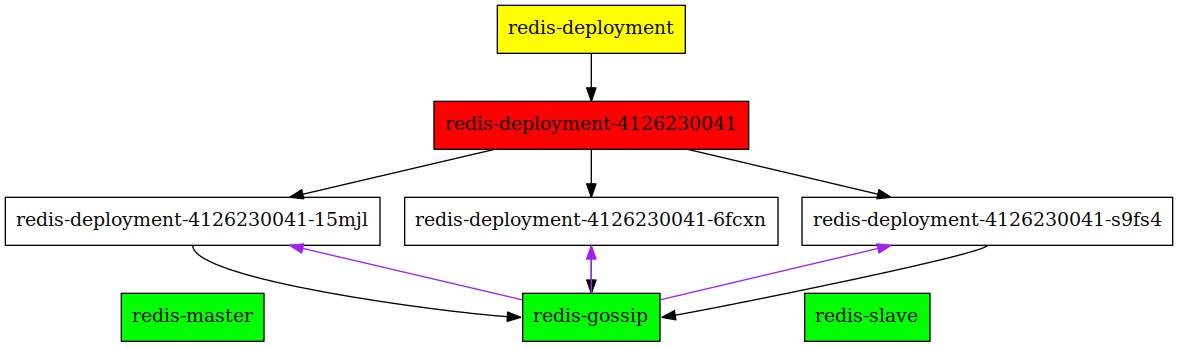
Actual situation: the supervisors will try to connect to themselves, causing a deadlock.
The solution
To solve this problem, we need to break the cyclic dependency that we have created; we need to have a special case for the initial supervisor.
Luckily kubernetes supports StatefulSets, which allow pods to have stable identifier names, and a guaranteed startup order.
Unfortunately, this makes it impossible to use the Deployments directly. The solution I have come up with is to create a StatefulSet that will act as a bootstrap service for other Deployments.
To make the supervisor in the StatefulSet pods start correctly, I augment the container generated by Habitat with a small ruby script, that determines what the arguments to the habitat supervisor must be.
The first pod in the Statefulset (with the name hab-sup-boostrap-0) will not have any --peer flag, the second will point to just hab-sup-bootstrap-0, the third to both hab-sup-bootstrap-0 and hab-sup-bootstrap-1 etc.
Our redis cluster can just point to the stable hab-bootstrap name to bootstrap the gossiping (purple arrows)
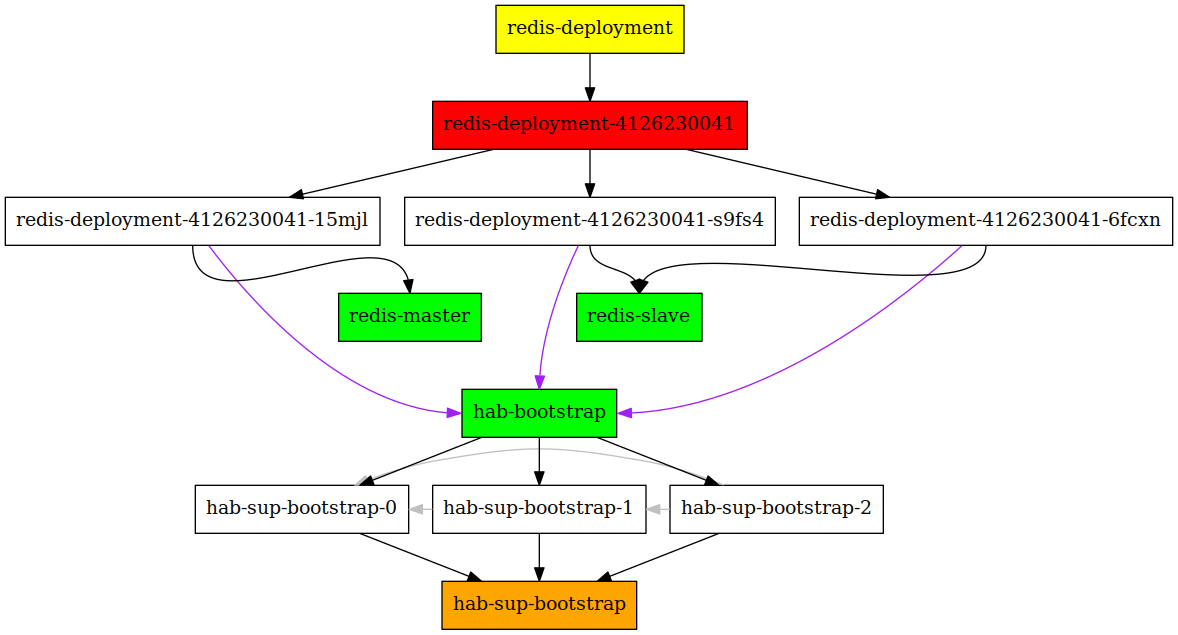
Final result: a hab-sup-bootstrap StatefulSet, with three pods, which back the hab-bootstrap service. The grey arrows show which --peer arguments are given to the hab-sup-bootstrap-$x pod. Redis can still be deployed as a Deployment; the cyclic dependency is broken.
Remaining problems
AFAICS there is one remaining source of race issues. If the hab-sup-bootstrap-0 pod dies, and is restarted, it might take some (smallish) amount of time before the other bootstrap supervisors notice that it's up again, and join it.
During this interval, a split-brain problem could occur. Consider other habitat supervisors that run a leader topology, which might connect to hab-sup-bootstrap-0 and conclude that one of them is the leader, whilst actually there are older pods that are just connected to hab-sup-bootstrap-{1,2}.
I believe this can only be fixed if the supervisors would have a flag to force connecting it to all IP addresses that are resolved by the service IP.
Running it yourself
Check out the instructions on GitHub.